-
Project: Hardware-Efficient Rigid Body Dynamics Acceleration for Agile Robotics
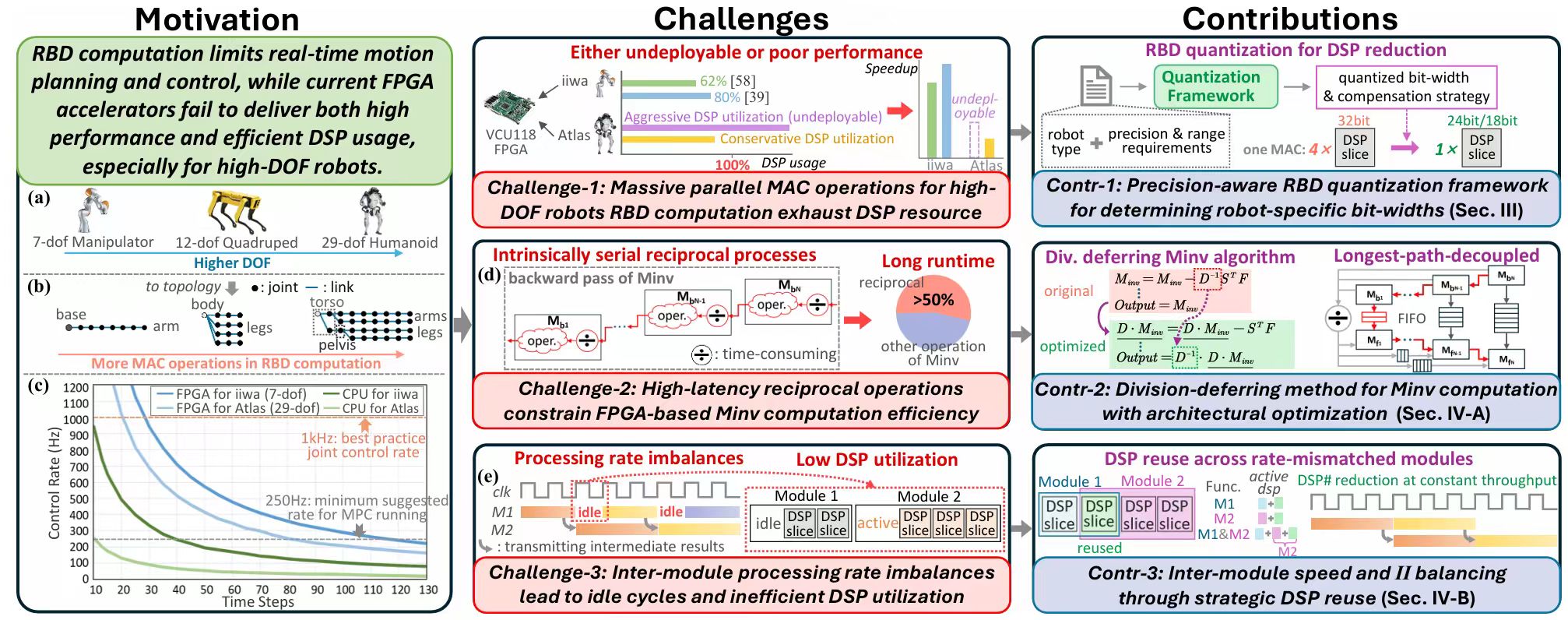
Rigid Body Dynamics (RBD) computation is a critical component of robotic planning and control, dominating system runtime due to its algorithmic complexity. As robots scale to higher degrees of freedom, existing hardware accelerators struggle with resource exhaustion and imbalanced processing pipelines. This project investigates algorithm-hardware co-design methodologies to develop scalable FPGA accelerators for complex robotic dynamics. Our research focuses on precision-aware quantization frameworks to reduce hardware demands while preserving motion accuracy, algorithmic reformulations to decouple complex operations from critical latency paths , and inter-module resource reuse architectures to maximize hardware utilization. Ultimately, this project aims to provide flexible accelerator templates that enable high-frequency control strategies, improving the agility and stability of autonomous robots in dynamic environments.
-
Project: Efficient 3D Vision System for Physical AI
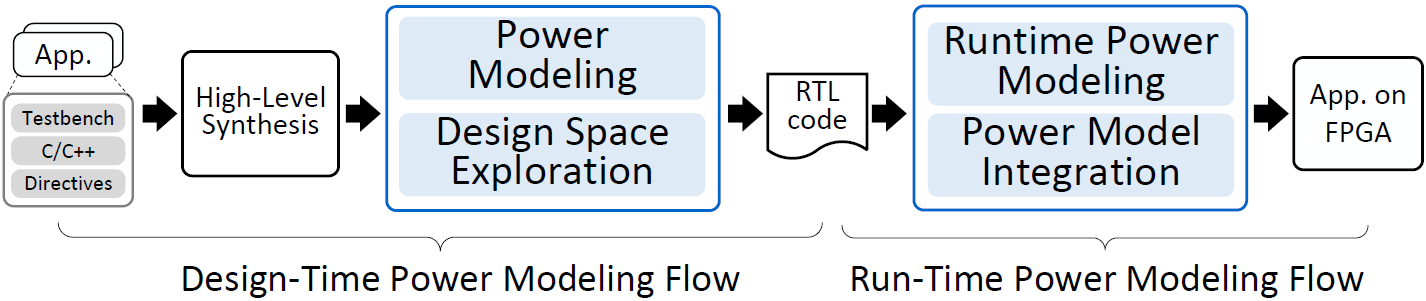
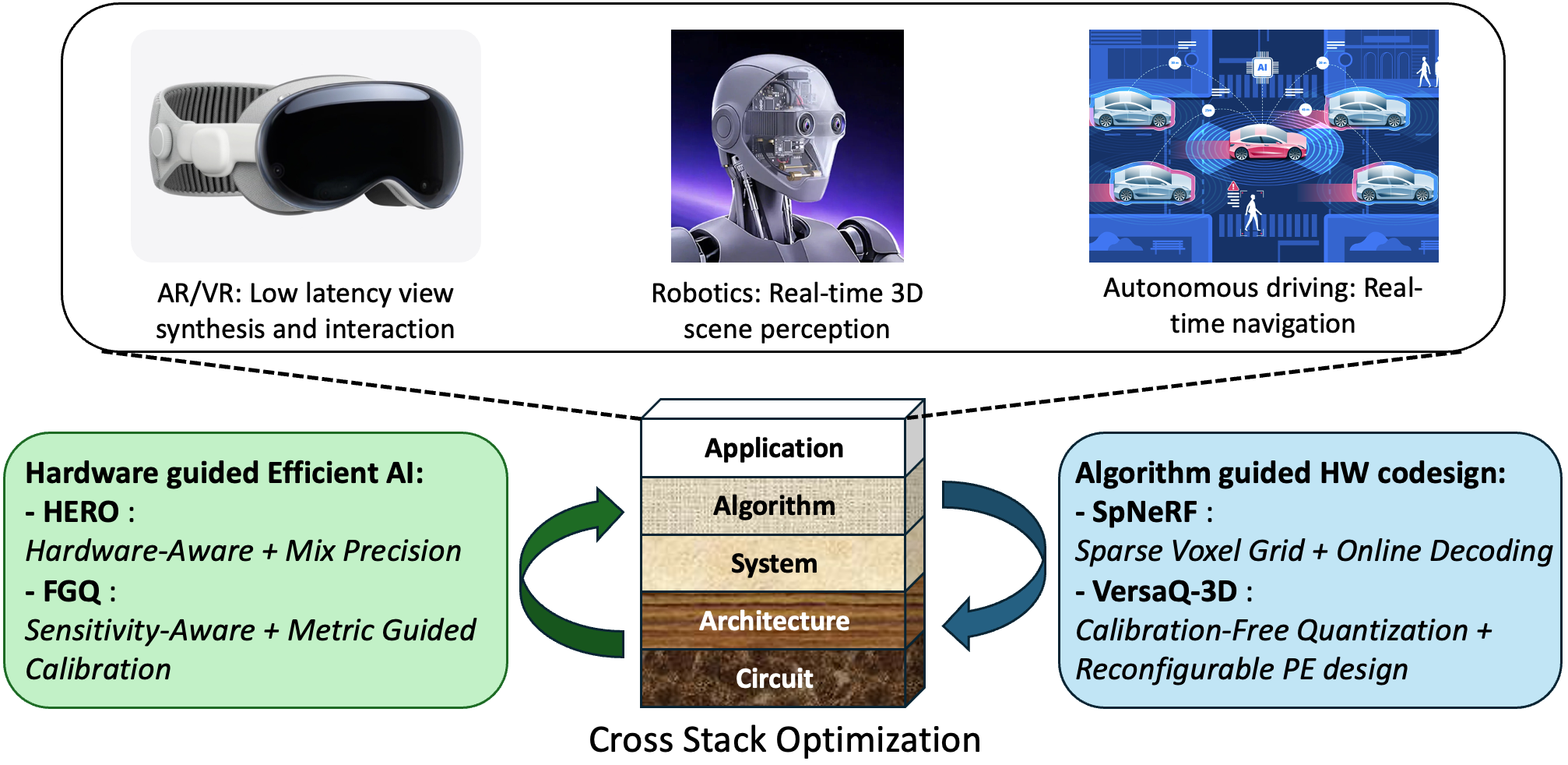
3D vision is a key enabler of real-time spatial intelligence for Physical AI applications, including AR/VR, robotics, and autonomous driving. However, deploying 3D vision systems on edge devices is challenging due to limited DRAM bandwidth, constrained on-chip SRAM capacity, tight compute resources, and strict energy budgets. To address these memory, bandwidth, compute, and energy bottlenecks, our work explores cross-stack optimization for efficient 3D vision. From the hardware-guided efficient AI perspective, HERO leverages hardware-aware mixed precision, while FGQ introduces sensitivity-aware and metric-guided calibration. From the algorithm-guided hardware codesign perspective, SpNeRF combines sparse voxel grids with online decoding, and VersaQ-3D enables calibration-free quantization with a reconfigurable processing-element design. Together, these works advance efficient, scalable, and edge-deployable 3D vision systems for Physical AI.
- 3D vision enables real-time spatial intelligence for AR/VR, robotics, and autonomous driving.
-
Edge deployment is required for low latency, privacy, and communication efficiency, but edge devices are constrained by:
① Limited DRAM bandwidth ② Limited on-chip SRAM ③ Tight energy budget - Edge bottleneck: memory capacity + bandwidth + compute + energy
-
Project: Towards Efficient and Scalable Acceleration of Online Decision Tree Learning on FPGA
Decision trees are machine learning models commonly used in various application scenarios. In the era of big data, traditional decision tree induction algorithms are not suitable for learning large-scale datasets due to their stringent data storage requirement. Online decision tree learning algorithms have been devised to tackle this problem by concurrently training with incoming samples and providing inference results. However, even the most up-to-date online tree learning algorithms still suffer from either high memory usage or high computational intensity with dependency and long latency, making them challenging to implement in hardware. To overcome these challenges, we introduce a new quantile-based algorithm to improve the induction of the Hoeffding tree, one of the state-of-the-art online learning models. The proposed algorithm is light-weight in terms of both memory and computational demand, while still maintaining high generalization ability. A series of optimization techniques dedicated to the proposed algorithm have been investigated from the hardware perspective, including coarse-grained and fine-grained parallelism, dynamic and memory-based resource sharing, pipelining with data forwarding. We further present a high-performance, hardware-efficient and scalable online decision tree learning system on a field-programmable gate array (FPGA) with system-level optimization techniques. Please refer to [C74] for more details.

-
Project: Optimizing OpenCL-based CNN Design on FPGA with Comprehensive Design Space Exploration and Collaborative Performance Modeling
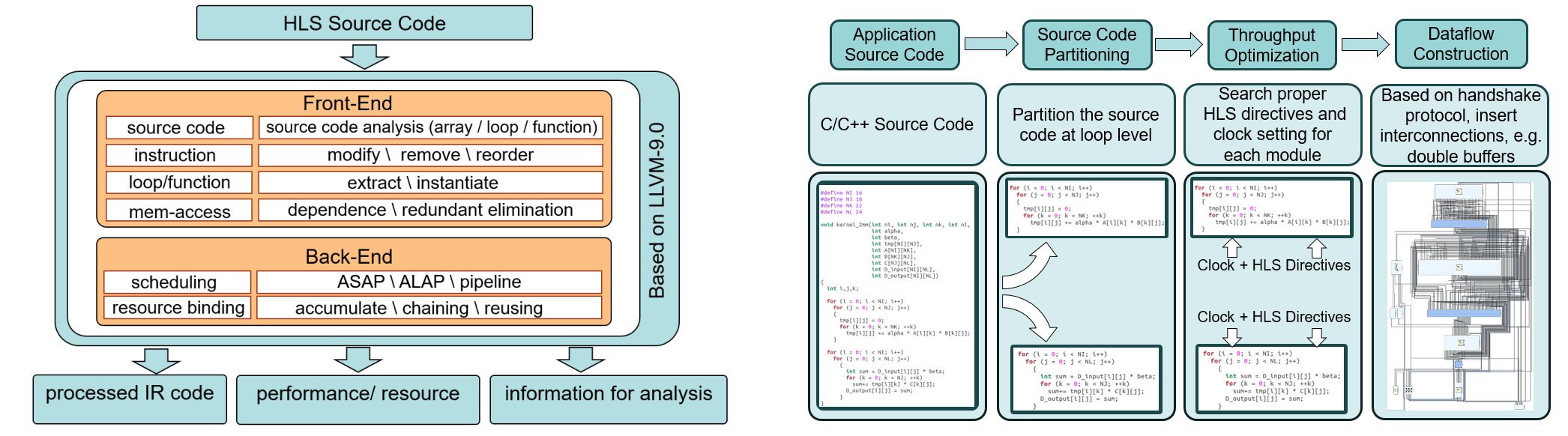
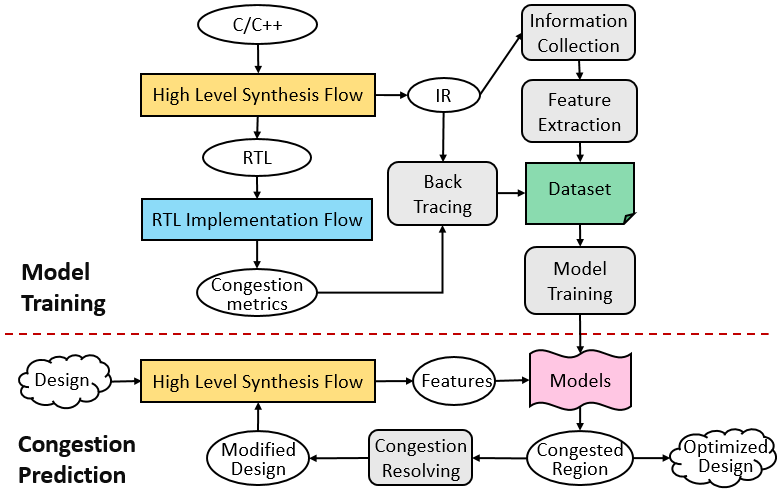
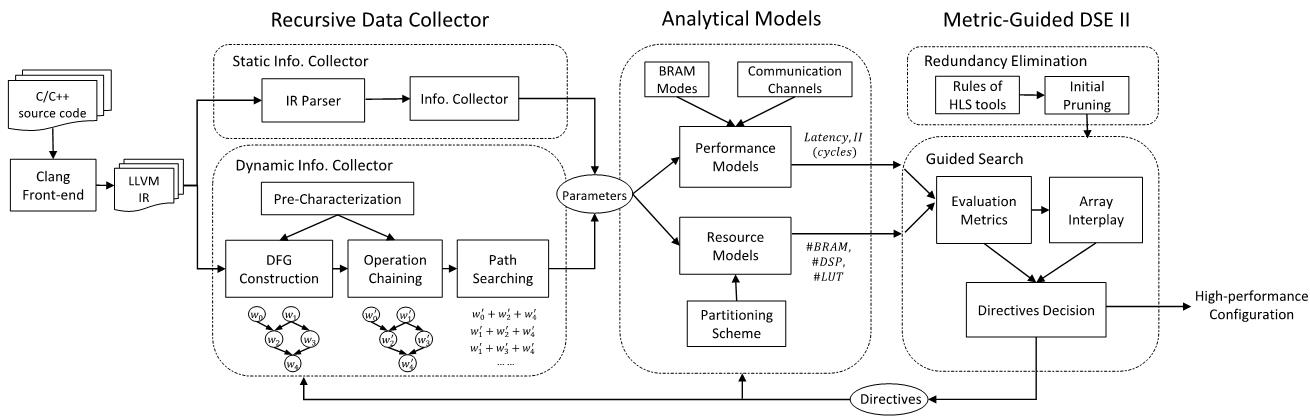
Recent success in applying CNNs to object detection and classification has sparked great interest in accelerating CNNs using hardware like FPGAs. However, finding an efficient FPGA design for a given CNN model and FPGA board is non-trivial. In this work, we try to solve this problem by design space exploration with a collaborative framework, which consists of three main parts: FPGA design generation, coarse-grained modeling, and fine-grained modeling. In the FPGA design generation, we propose a novel data structure, LoopTree, to capture the details of the FPGA design for CNN applications without writing down the source code. Different LoopTrees are automatically generated in this process. A coarse-grained model will evaluate LoopTrees at the operation level so that the most efficient LoopTrees can be selected. A fine-grained model, which is based on the source code, will then refine the selected design in a cycle-accurate manner. A set of comprehensive OpenCL-based designs have been implemented onboard to verify our framework. An average estimation error of 8.87% and 4.8% have been observed for our coarse-grained model and fine-grained model, respectively.

-
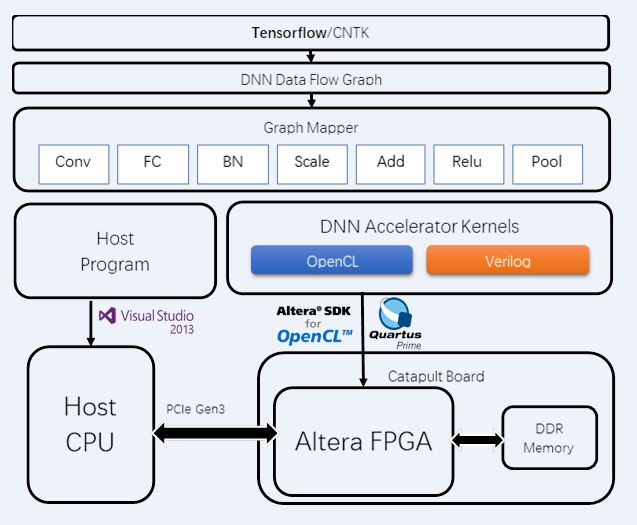
Project: FP-DNN: An Automated Framework for Mapping Deep Neural Networks onto FPGAs with RTL-HLS Hybrid Templates
DNNs (Deep Neural Networks) have demonstrated great success in numerous applications such as image classification, speech recognition, video analysis, etc. However, DNNs are much more computation-intensive and memory-intensive than previous shallow models. Thus, it is challenging to deploy DNNs in both large-scale data centers and real-time embedded systems. Considering performance, flexibility, and energy efficiency, FPGA-based accelerator for DNNs is a promising solution. Unfortunately, conventional accelerator design flows make it difficult for FPGA developers to keep up with the fast pace of innovations in DNNs. To overcome this problem, we propose FP-DNN (Field Programmable DNN), an end-to-end framework that takes TensorFlow-described DNNs as input, and automatically generates the hardware implementations on FPGA boards with RTL-HLS hybrid templates. FP-DNN performs model inference of DNNs with our high-performance computation engine and carefully-designed communication optimization strategies. We implement CNNs, LSTM-RNNs, and Residual Nets with FPDNN, and experimental results show the great performance and flexibility provided by our proposed FP-DNN framework.
-
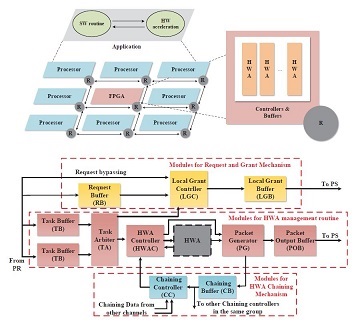
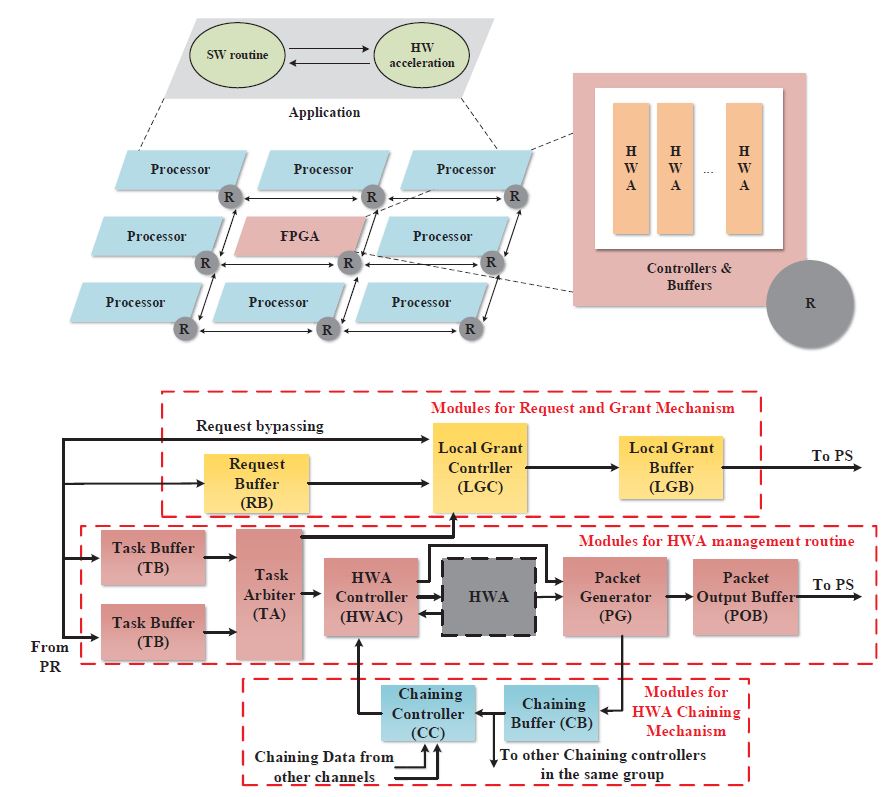
Project: Scalable Light-Weight Integration of FPGA Based Accelerators with Chip Multi-Processors
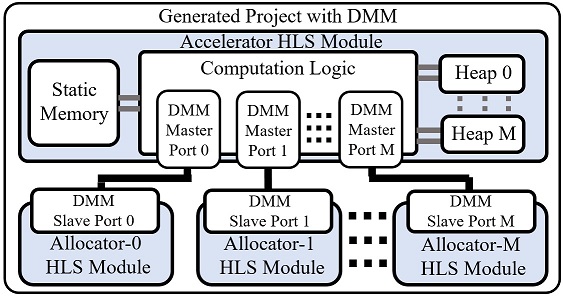
Modern multicore systems are migrating from homogeneous systems to heterogeneous systems with accelerator-based computing in order to overcome the barriers of performance and power walls. In this trend, FPGA-based accelerators are becoming increasingly attractive, due to their excellent flexibility and low design cost. In this project, we propose the architectural support for efficient interfacing between FPGA-based multi-accelerators and chip-multiprocessors (CMPs) connected through the network-on-chip (NoC). Distributed packet receivers and hierarchical packet senders are designed to maintain scalability and reduce the critical path delay under a heavy task load. A dedicated accelerator chaining mechanism is also proposed to facilitate intra-FPGA data reuse among accelerators to circumvent prohibitive communication overhead between the FPGA and processors. In order to evaluate the proposed architecture, a complete system emulation with programmability support is performed using FPGA prototyping. Experimental results demonstrate that the proposed architecture has high-performance, and is light-weight and scalable in characteristics. Please refer to [J41] for more details.
-
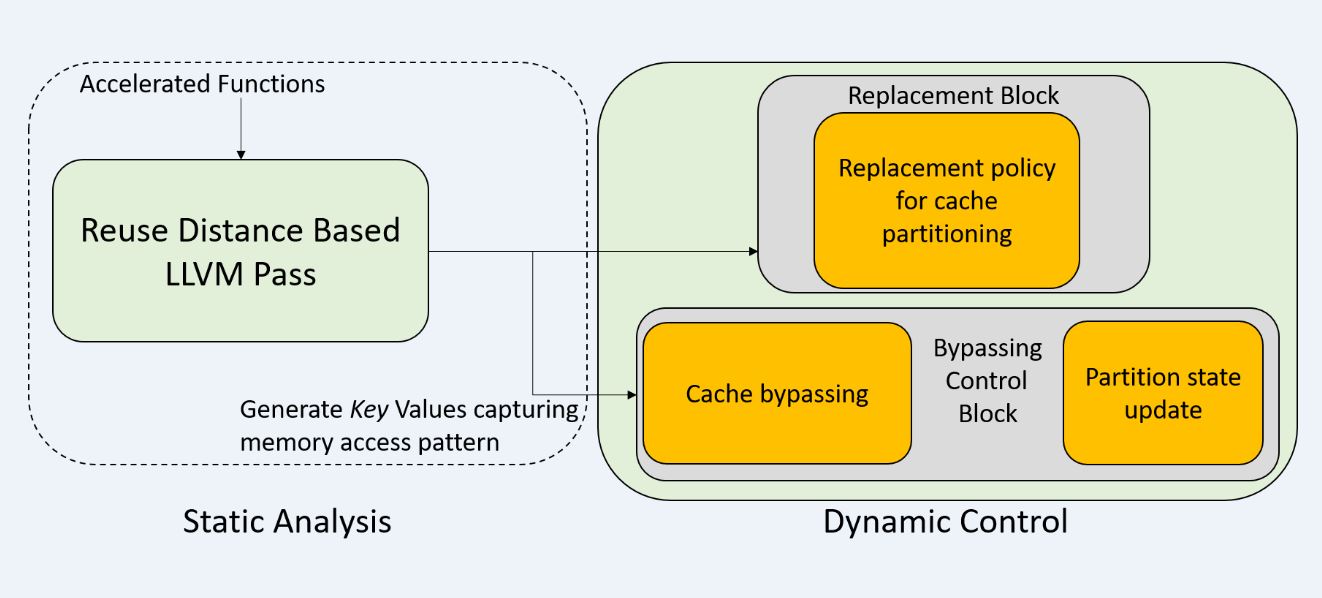
Project: A Hybrid Approach to Cache Management in Heterogeneous CPU-FPGA Platforms
Heterogenous computing is gaining increasing attention due to its promise of high performance with low power. Shared coherent cache based CPU-FPGA platforms, like Intel HARP, are a particularly promising example of such systems with enhanced efficiency and high flexibility. In this work, we propose a hybrid strategy that relies on both static analysis of applications and dynamic control of cache driven by such static analysis to minimize contention on the coherent FPGA cache in emerging shared coherent cache based CPU-FPGA platforms. We develop an LLVM pass, based on reuse distance theory, to analyze memory access patterns of the application kernels to be executed on FPGA and generate kernel characteristics called Key values. Thereafter, a dynamic scheme for cache bypassing and partitioning based on these Key values is proposed to increase the cache hit rate and improve the overall performance. Experiments using a number of benchmarks show that the proposed strategy can increase the cache hit rate by 22.90% on average and speed up the application by up to 12.52%.
-
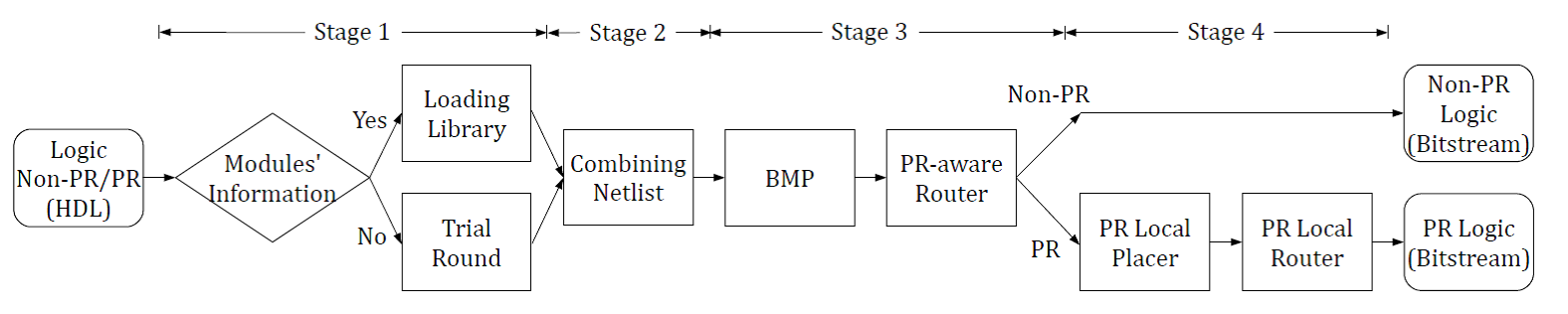
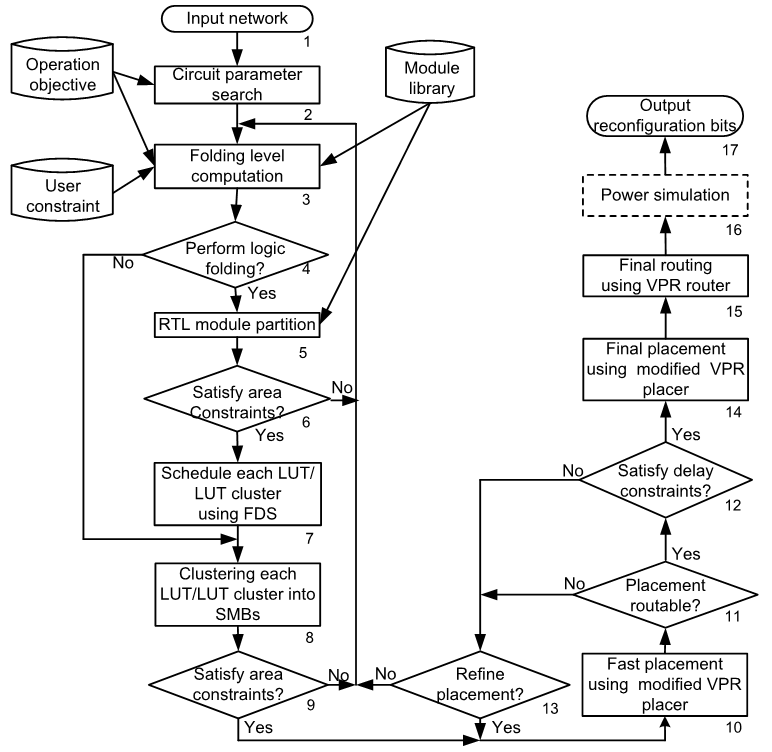
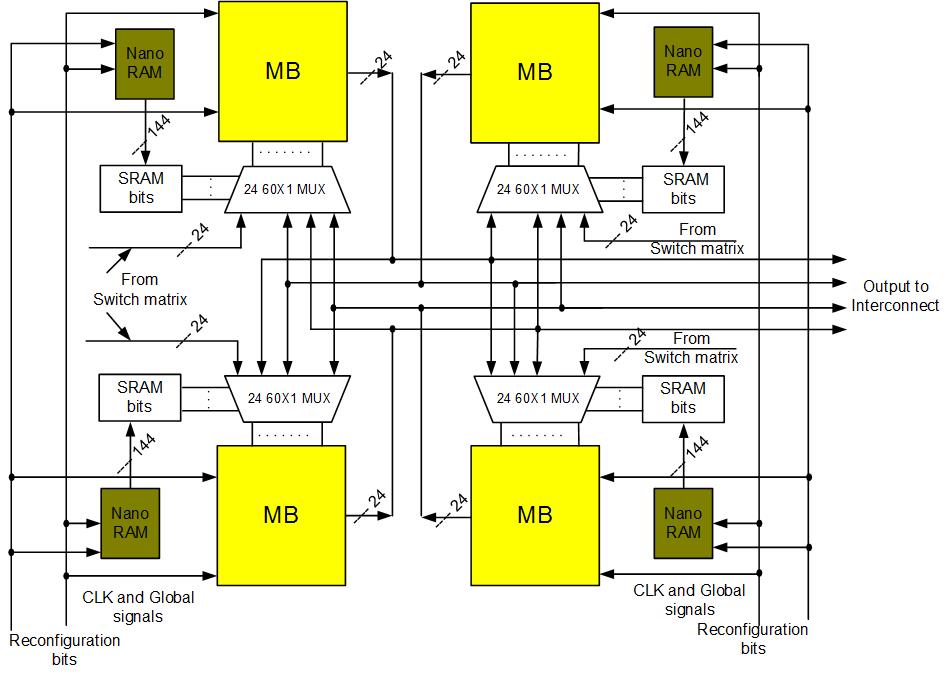
Project: Dynamically reconfigurable architecture for closing the FPGA/ASIC gap while providing superior design flexibility
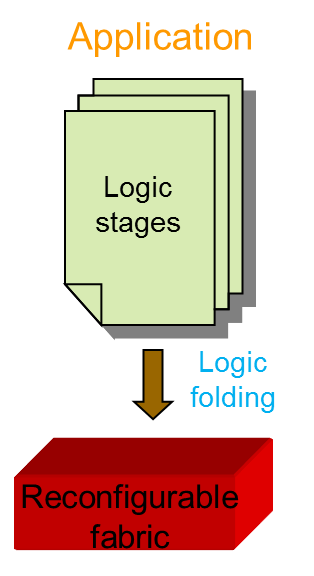
Current FPGA design faces many challenges such as low logic utilization and long reconfiguration delay. The gap between ASIC and FPGA is big in terms of area, delay and power consumption, which reduces the advantages of FPGA devices for embedded system. We proposed hybrid CMOS/nanotechnology dynamically reconfigurable architectures, including NATURE and FDR, to overcome the logic density and reconfiguration efficiency obstacles. We use CMOS logic and interconnects, aided by on-chip nano-electronic RAMs that store reconfiguration bits. It uses the concept of temporal logic folding and fine-grain (i.e., cycle-level) dynamic reconfiguration to bring significant benefits. An over 10X improvement in area-delay product and 2X power reduction can be obtained compared to traditional FPGA implementations, which effectively reduced the gap between reconfigurable architecture and ASIC. We further augment the design with integrated coarse-grained blocks, such as DSP and block memory, new technologies, such as 3D integration and FinFET, to significantly improve the performance and reduce the power consumption of the architecture.
-
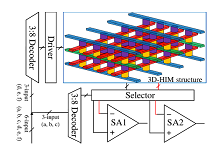
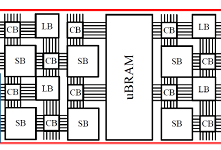
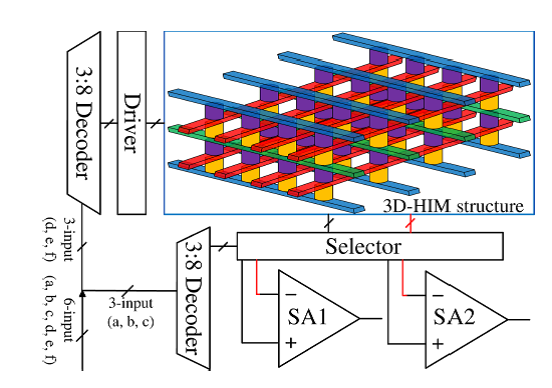
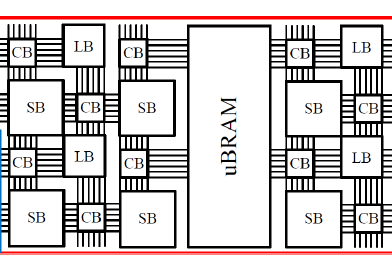
Project: Non-volatile 3D stacking RRAM-based FPGA with unified data/configuration memory
The existing FPGA products keep the configured logics and signal routing information in the SRAM to realize the required functionalities. The fast development of emerging memory techniques, such as the Resistive Random Access Memory (RRAM), has demonstrated significant advantages compared to traditional memory techniques including high density, low power consumption, comparable access speed and non-volatility. We proposed a new FPGA architecture that can completely substitute RRAM for SRAM in all the major components including the logic blocks (LB), switch blocks (SB) and connection blocks (CB). The look-up-table (LUT) design in LB can be engineered in 3D stacking to maximize the benefits from the high density of RRAM. It naturally supports bit-addressable access and can be used as Distributed Random Access Memory (D-RAM), which usually has limited utilization in the conventional SRAM-based FPGAs due to high design complexity and large area. The routing controls in SB and CB utilize the complementary RRAM cells of the crossbar structure. We keep the design of pass gate used in the conventional FPGA to transfer signals for better performance. However, owe to the high density of RRAM, the large number of configuration memory cells associated with the pass gates is no longer a problem. Since the area is improved with smaller area owe to RRAM cells, the delay along the critical path is also reduced because of shorter connection. Experimental results on benchmarks show 62.7% area reduction with 34% delay improvement of this hardware architecture compared to conventional FPGA. Since each LUT is bit-addressable, which enables the run-time fast access, it also can be used together with dynamically reconfigurable architecture and improve the flexibility of the architecture. We take this advantage and propose the unified Block RAM (BRAM) structure which combines the on-chip data memory and configuration memory. With this design, the RRAM-based FPGA can perform run-time fast reconfiguration when needed. While the reconfiguration is not needed, the configuration memory can be replaced with data memory for temporary data storage. Hence no explicit area overhead is incurred. The design hides the configuration memory area but can support the run-time reconfiguration when needed.


")
")
")
")