-
AMF-Placer: High-Performance Analytical Mixed-size Placer for FPGA
AMF-Placer is an open-source analytical mixed-size FPGA placer supporting mixed-size placement on FPGA, with an interface to Xilinx Vivado. To speed up the convergence and improve the quality of the placement, AMF-Placer is equipped with a series of new techniques for wirelength optimization, cell spreading, packing, and legalization. Based on a set of the latest large open-source benchmarks from various domains for Xilinx Ultrascale FPGAs, experimental results indicate that AMF-Placer can improve HPWL by 20.4%-89.3% and reduce runtime by 8.0%-84.2%, compared to the baseline. Furthermore, utilizing the parallelism of the proposed algorithms, with 8 threads, the placement procedure can be accelerated by 2.41x on average. [Source Code]
")
")
")
")
AMF-Placer
-
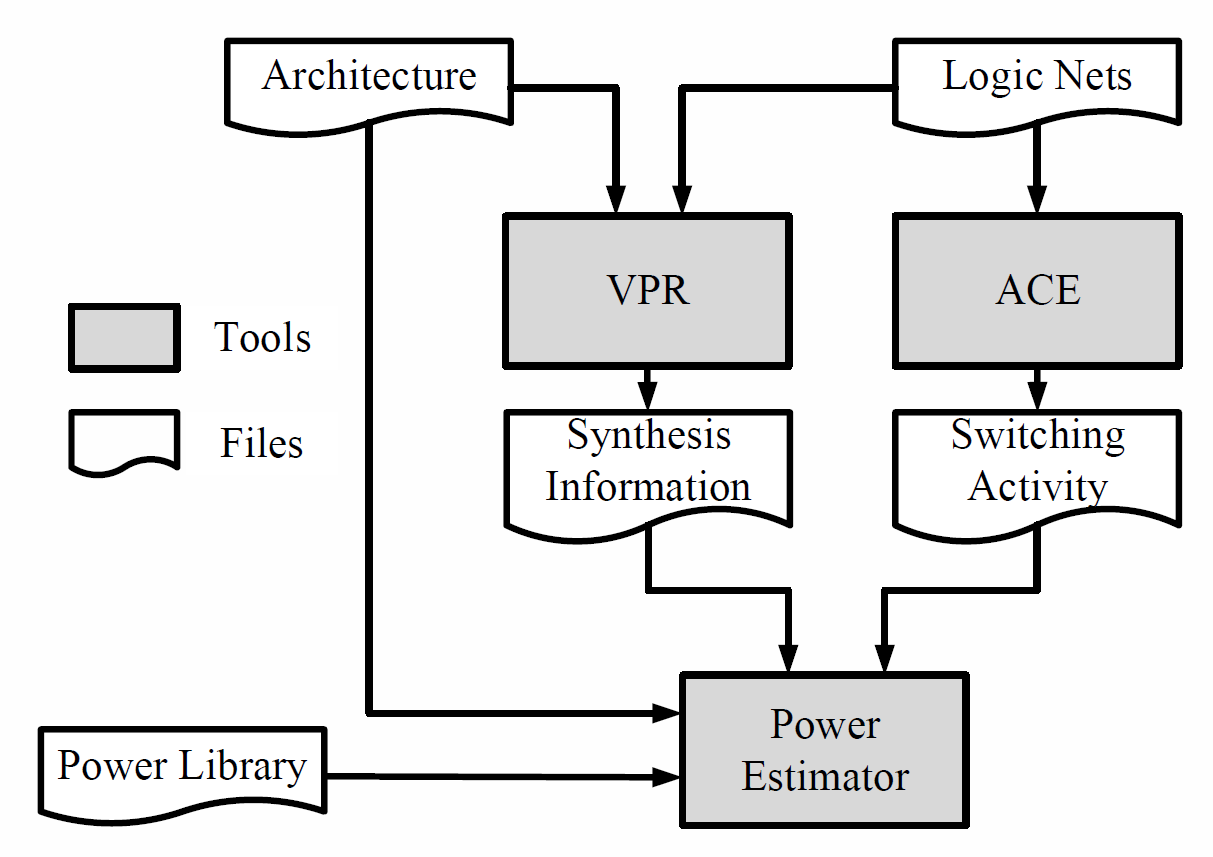
Hi-ClockFlow: Multi-Clock Dataflow Automation and Throughput Optimization in High-Level Synthesis
[Hi-ClockFlow], an automatic HLS framework, can analyze the source code based on [Light-HLS] (our light-weight yet accurate HLS evaluation framework), explore the large design space, and optimize such parameters as clock frequencies and HLS directives in dataflow. By properly partitioning the source code into parts with various clock domains, Hi-ClockFlow can optimize the dataflow with imbalanced modules and speed up the performance under the specific constraint of resource.
-
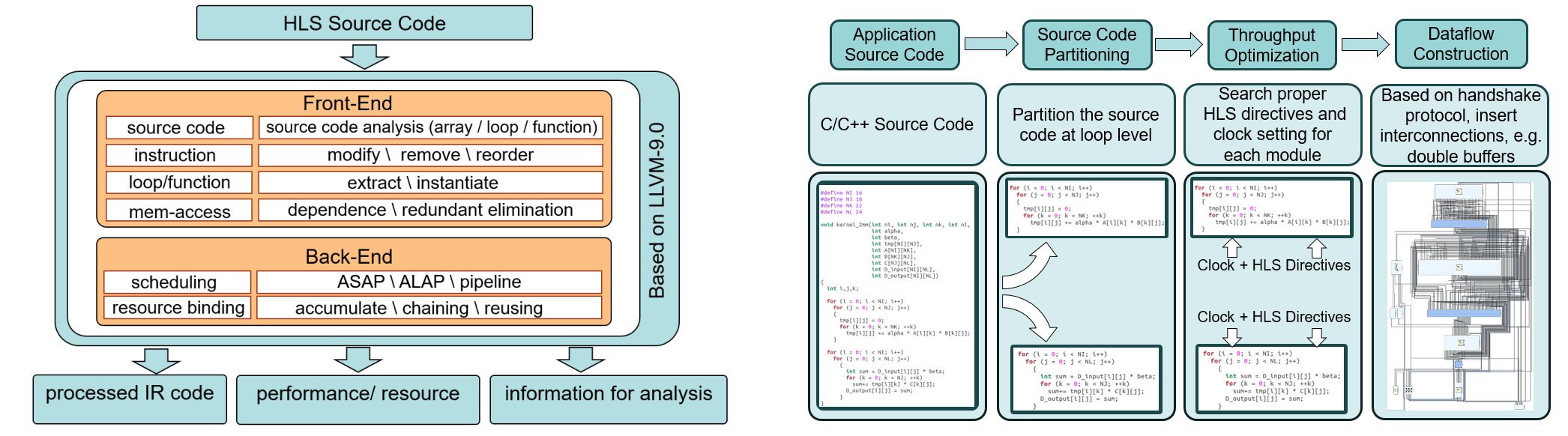
Hi-DMM: High-Performance Dynamic Memory Management in High-Level Synthesis
Hi-DMM is proposed as a dynamic memory allocation and management scheme, for inclusion in commercial HLS design flows. Hi-DMM performs source-to-source transformation of user C code with dynamic memory constructs into C-source code with the dynamic memory allocator and management scheme developed in this work. The transformed C-source code is amenable to synthesis by commercial tools like Vivado HLS. Relying on buddy tree-based allocation schemes and efficient hardware implementation of the allocators, Hi-DMM achieves 4x speed-up in both fine-grained and coarse-grained memory allocation compared to previous works. [Source Code]
Hi-DMM
-
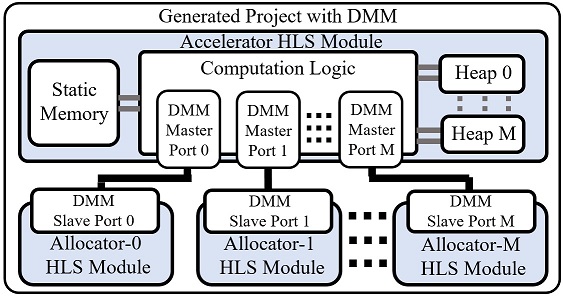
COMBA: A Comprehensive Model-Based Analysis Framework for High Level Synthesis of Real Applications
COMBA is an automatic model-based analysis framework, which is capable of analyzing the effects of a multitude of directives related to functions, loops and arrays in the design description. The proposed automatic framework includes pluggable analytical models for the estimation of performance and resource usage, a recursive data collector to compute necessary parameters for the analytical models and a metric-guided design space exploration algorithm to find the high-performance configurations rapidly. [Source Code]
COMBA
-
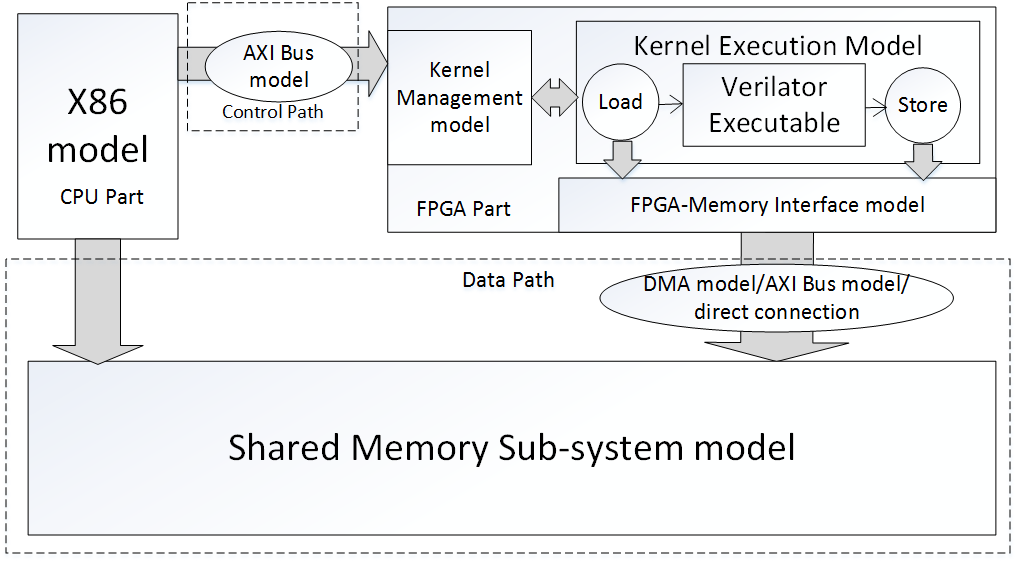
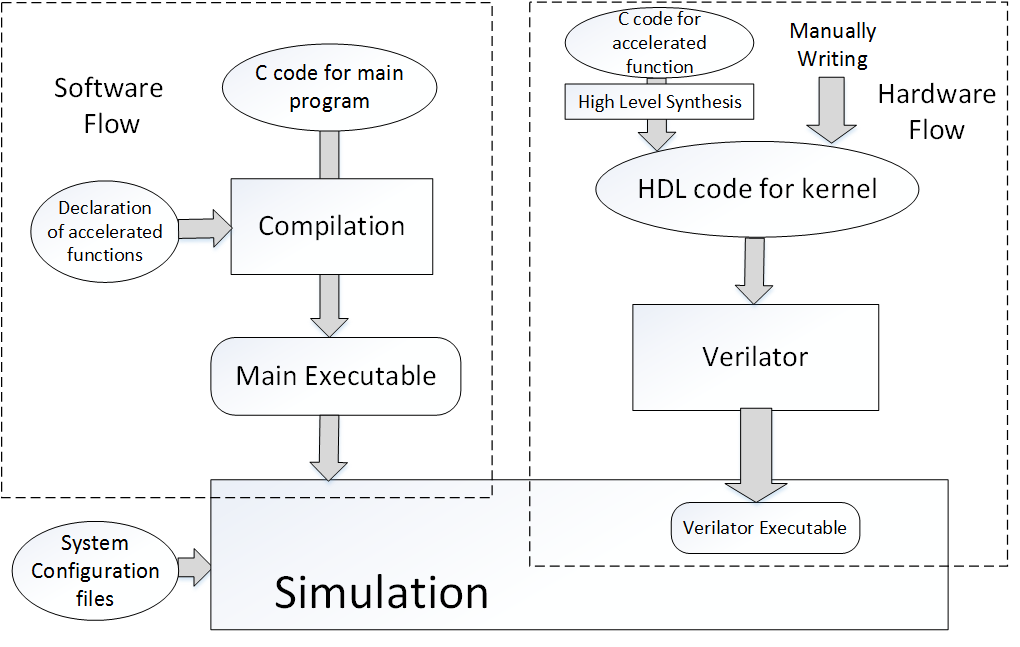
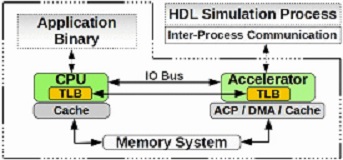
PAAS: A system level simulator for heterogeneous computing architectures
CPU-accelerator integrated architectures, such as CPU with ASIC or FPGA based accelerators, are able to provide customized processing according to application requirements and are thus particularly attractive to speed up computation-intensive applications. Therefore, system level simulation showing the interaction among CPUs, hardware accelerators and memory system precisely is important for performing design space exploration leading to architecture and design optimization. We present PAAS (Processor Accelerator Architecture Simulator), a system level simulator to enable cycle-accurate full system simulation of CPU-accelerator heterogeneous systems. PAAS can easily support flexible architectural configurations, such as different on-chip interconnection topologies, memory hierarchy, etc. Compared to previous tools, PAAS supports shared coherent caches between CPUs and accelerators, shared virtual address space between accelerators and threads of CPUs and runtime control of multiple accelerators. Specially for FPGA-based accelerators, PAAS can simulate the reconfiguration of FPGA. Parallelism has been implemented in PAAS to speed up the simulation. [Reference] [Source Code]
PAAS
-
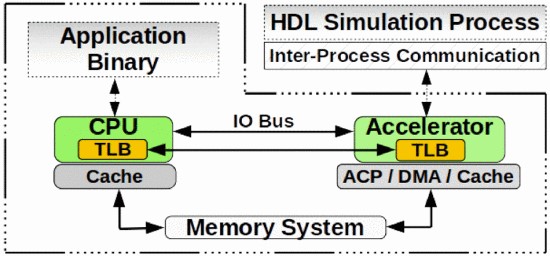
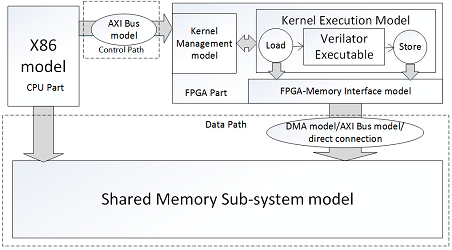
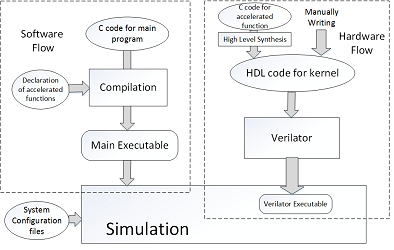
HeteroSim: A Heterogeneous CPU-FPGA Simulator
Heterogeneous Computing is a promising new direction to address the challenges of performance and power walls in computing. In this aspect, CPU-FPGA combination architectures are particularly interesting to speed up a wide range of applicationsrecognition, mining, search, big data analytics etc. However, the design, development and simulation of these architectures together with associated memory hierarchies is particularly challenging due to the absence of an integrated simulator that could support full system simulation and architectural exploration. In the current work, we present HeteroSim which is a full system simulator supporting x86 multicore processors combined with a FPGA via bus-based architecture. It affords architecture exploration with respect to number of processor cores, number of hardware accelerated kernels mapped on FPGA, cache coherent communication between processor cores and FPGA and Direct Memory Access (DMA). It performs full system simulation and returns various performance metrics to understand application performance with respect to the simulated architectural configuration. Using benchmarks applications from different domains, we demonstrate the flexibility of HeteroSim through the architectural exploration of CPU-FPGA system. [Reference] [Source Code]
HeteroSim
-
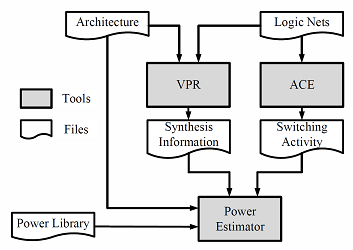
Hierarchical Library Based Power Estimator for Versatile FPGAs
FPGA is a promising hardware accelerator in modern high-performance computing systems, e.g. cloud computing, big-data processing, etc. In such a system, power is a key factor of the design requiring thermal and energy-saving considerations. Modern power estimators for FPGA either support specific hardware provided by vendors or contain power models for certain types of conventional FPGA architectures. However, with technology advancement, novel FPGA of versatile architectures are introduced to further augment current FPGA architecture at various aspects, such as emerging FPGA with non-volatile memory, nanowire interconnection of reconfigurable array, etc. To evaluate the power consumption of various FPGA designs, the power estimator has to be made more flexible and extendable for supporting new devices and architectures. We introduce in this paper a novel power estimator with hierarchical library supporting power models at different levels, e.g. novel circuit of components, emerging memory devices, architecture of timemultiplexing fashion, etc. The power estimator also supports coarse-grain or fine-grain power estimation defined by users for achieving complexity-accuracy trade-off. Simulation results of benchmarks of our power estimator against commercial one demonstrate accuracy of our tool. Furthermore, we present an example of RRAM FPGA power estimation, which has novel memory devices and potential of power gating. Our tool demonstrates flexibility to well support, but not limited to, the power estimation of such state-of-the-art FPGAs. [Reference] [Source Code]
HPowerEstimator